from lightrag.llm import hf_model_complete, hf_embedding from transformers import AutoModel, AutoTokenizer from lightrag.utils import EmbeddingFunc
# Initialize LightRAG with Hugging Face model rag = LightRAG( working_dir=WORKING_DIR, llm_model_func=hf_model_complete, # Use Hugging Face model for text generation llm_model_name='meta-llama/Llama-3.1-8B-Instruct', # Model name from Hugging Face # Use Hugging Face embedding function embedding_func=EmbeddingFunc( embedding_dim=384, max_token_size=5000, func=lambda texts: hf_embedding( texts, tokenizer=AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2"), embed_model=AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") ) ), )
3 支持ollama模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
from lightrag.llm import ollama_model_complete, ollama_embedding from lightrag.utils import EmbeddingFunc
# Initialize LightRAG with Ollama model rag = LightRAG( working_dir=WORKING_DIR, llm_model_func=ollama_model_complete, # Use Ollama model for text generation llm_model_name='your_model_name', # Your model name # Use Ollama embedding function embedding_func=EmbeddingFunc( embedding_dim=768, max_token_size=8192, func=lambda texts: ollama_embedding( texts, embed_model="nomic-embed-text" ) ), )
修改了模型需要重新构建新目录,否则部分参数会报错
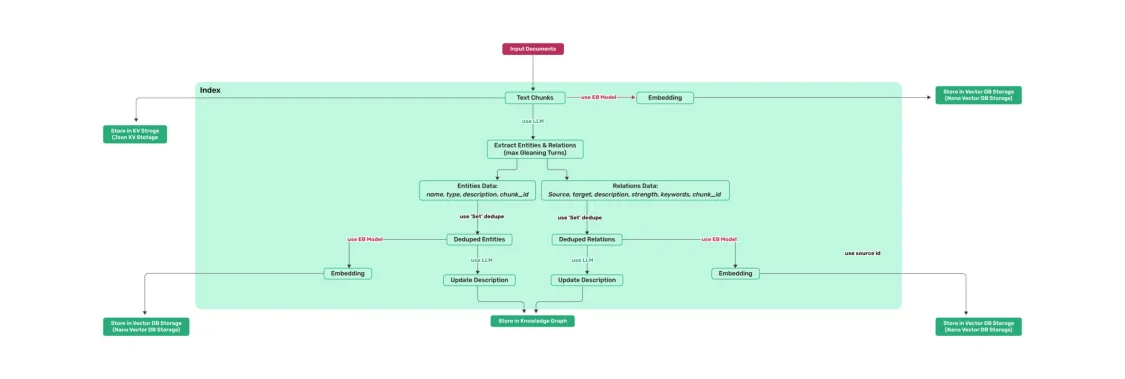
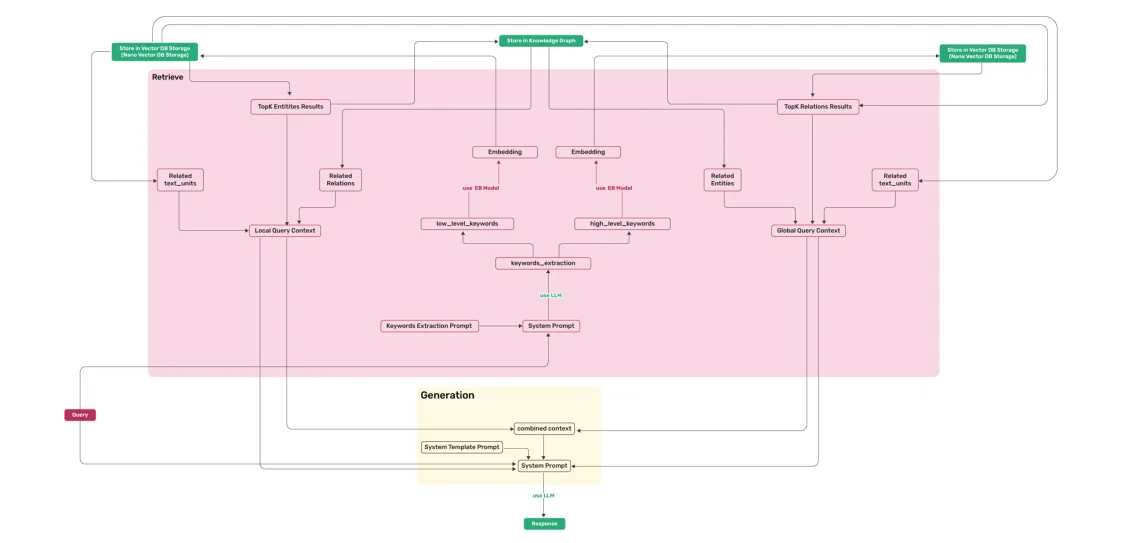
基本操作
查询参数
可以设置查询时的参数,如检索模式、topk等
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classQueryParam: mode: Literal["local", "global", "hybrid", "naive"] = "global" only_need_context: bool = False response_type: str = "Multiple Paragraphs" # Number of top-k items to retrieve; corresponds to entities in "local" mode and relationships in "global" mode. top_k: int = 60 # Number of tokens for the original chunks. max_token_for_text_unit: int = 4000 # Number of tokens for the relationship descriptions max_token_for_global_context: int = 4000 # Number of tokens for the entity descriptions max_token_for_local_context: int = 4000
print(rag.query("What are the top themes in this story?", param=QueryParam(mode="naive")))
增量添加文档数据
与初始化图谱类似,执行insert操作即可。
1 2
withopen("./newText.txt") as f: rag.insert(f.read())
 wechat
wechat